


NRNS: No RL, No Simulation
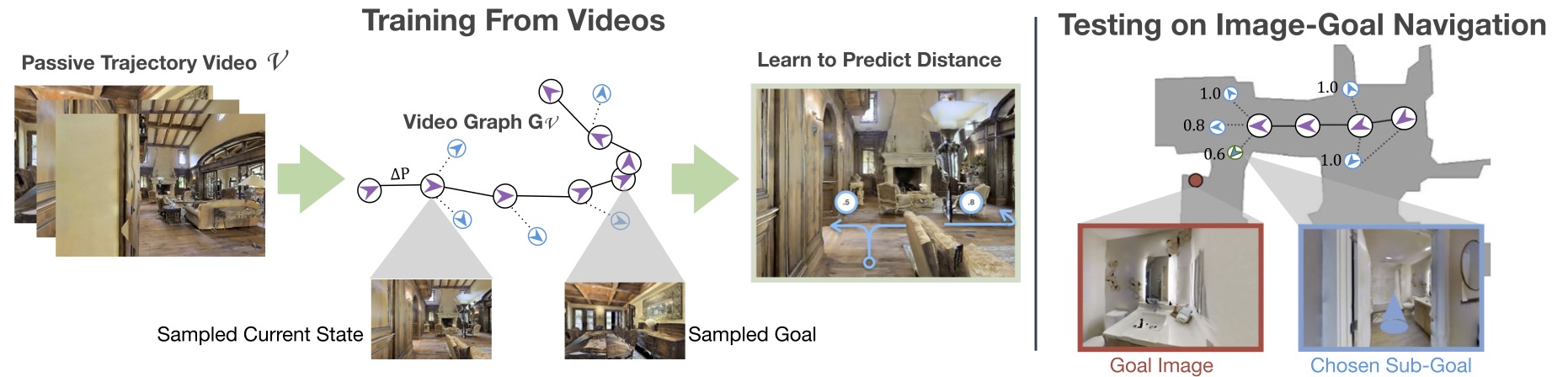
We pose a simple question: Do we really need active interaction, ground-truth maps or even reinforcement-learning (RL) in order to solve the image-goal navigation task? We propose a self-supervised approach to learn to navigate from only passive videos of roaming and demonstrate the success of this approach on Image-Goal navigation in unseen environments. The No RL, No Simulator (NRNS) is a hierarchical modular approach that builds and maintains a topological map. Using a passively trained distance function and target direction prediction function the agent selects and navigates to sub-goals before terminating at the predicted goal location. We gather passive videos from random walks in simulators and YouTube and use these videos to train the NRNS modules.
Task: Image-Goal Navigation
We tackle the task of image-goal navigation, where an agent is placed in a novel environment, and is tasked with navigating to an (unknown) goal position that is specified using an image taken from that position. More formally, an episode begins with an agent receiving an RGB observation corresponding to the goal position. At each time step, of the episode the agent receives a set of observations, and must take a navigation action. The agents state observations, are defined as a narrow field of view RGBD, and egocentric pose estimate. The agent must use a policy to navigate to the goal before reaching a maximum number of actions.
News
September 2021 — Accepted to NeurIPS!
Paper
No RL, No Simulation: Learning to Navigate without Navigating

People





